18. Advanced NLP and Accounting/Finance#
import os
import gensim
import spacy
import nltk
from nltk.corpus import stopwords
nlp = spacy.load('en_core_web_lg', disable=['parser', 'ner'])
nlp.max_length = 5000000
stop_words = stopwords.words("english")
stop_words.extend(['proc','type','mic','clear','originator','name','webmaster','www','gov','originator',
'key','asymmetric','dsgawrwjaw','snkk','avtbzyzmr','agjlwyk','xmzv','dtinen','twsm',
'sdw','oam','tdezxmm','twidaqab','mic','info','rsa','md','rsa','kn','ln','cgpgyvylqm',
'covp','srursowk','xqcmdgb','mdyso','zjlcpvda','hx','lia','form','period','ended',])
source_dir = 'D:/Data/Reasonable_10K/'
def iter_documents(source_dir):
i=1
for root, dirs, files in os.walk(source_dir):
for fname in files:
document = open(os.path.join(root, fname)).read().split('</Header>')[1]
tokens = gensim.utils.simple_preprocess(document)
red_tokens = [token for token in tokens if token not in stop_words]
doc = nlp(" ".join(red_tokens))
lemmas = [token.lemma_ for token in doc if token.pos_ in ['NOUN']]
print(str(i),end = '\r',flush=True)
i+=1
yield lemmas
files_to_lemmas = iter_documents(source_dir)
dictionary = gensim.corpora.Dictionary(files_to_lemmas)
import pickle
# Save dump file
fp = open('dictionary.rdata','wb')
pickle.dump(dictionary,fp)
fp.close()
"# Save dump files\n\nfp = open('gender_samples.rdata','wb')\npickle.dump(bootstrap_samples_df,fp)\nfp.close()\n\nfp = open('gender_shaps.rdata','wb')\npickle.dump(bootstrap_shaps_df,fp)\nfp.close()"
# Load dump file
fp = open('dictionary.rdata','rb')
dictionary = pickle.load(fp)
fp.close()
dictionary.filter_extremes(no_below=10, no_above=0.5)
files_to_lemmas = iter_documents(source_dir)
corpus = [dictionary.doc2bow(lemmas) for lemmas in files_to_lemmas]
# Save dump file
fp = open('corpus.rdata','wb')
pickle.dump(dictionary,fp)
fp.close()
"# Save dump files\n\nfp = open('gender_samples.rdata','wb')\npickle.dump(bootstrap_samples_df,fp)\nfp.close()\n\nfp = open('gender_shaps.rdata','wb')\npickle.dump(bootstrap_shaps_df,fp)\nfp.close()"
# Load dump file
fp = open('corpus.rdata','rb')
dictionary = pickle.load(fp)
fp.close()
lda_model = gensim.models.ldamulticore.LdaModel(corpus=corpus,
id2word=dictionary,
num_topics=24,
random_state=100,
update_every=1,
chunksize=len(corpus)/20,
passes=100,
alpha='asymmetric',
per_word_topics=False,
minimum_probability=.0,
eta = 'auto')
# Save model
lda_model.save('first_model.lda')
# Load model
gensim.models.ldamulticore.LdaModel.load('first_model.lda')
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(lda_model, corpus, dictionary)
/home/mikkoranta/python3/gensim/lib/python3.8/site-packages/joblib/numpy_pickle.py:103: DeprecationWarning: tostring() is deprecated. Use tobytes() instead.
pickler.file_handle.write(chunk.tostring('C'))
/home/mikkoranta/python3/gensim/lib/python3.8/site-packages/joblib/numpy_pickle.py:103: DeprecationWarning: tostring() is deprecated. Use tobytes() instead.
pickler.file_handle.write(chunk.tostring('C'))
vis
import pandas as pd
top_words_df = pd.DataFrame()
for i in range(24):
temp_words = lda_model.show_topic(i,10)
just_words = [name for (name,_) in temp_words]
top_words_df['Topic ' + str(i+1)] = just_words
top_words_df.T.to_csv('topics.csv')
import datetime
from dateutil.parser import parse
files = os.listdir(source_dir)
file_dates = [parse(item.split('_')[0]) for item in files]
import numpy as np
evolution = np.zeros([len(corpus),25])
ind = 0
for bow in corpus:
topics = lda_model.get_document_topics(bow)
for topic in topics:
evolution[ind,topic[0]] = topic[1]
ind+=1
evolution_df = pd.DataFrame(evolution)
evolution_df['Date'] = file_dates
evolution_df.set_index('Date',inplace=True)
evolution_df
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||||||||||||||
| 1994-01-11 | 0.315972 | 0.002277 | 0.598000 | 0.001700 | 0.001509 | 0.001357 | 0.066930 | 0.001129 | 0.001041 | 0.000966 | ... | 0.000675 | 0.000643 | 0.000613 | 0.000586 | 0.000562 | 0.000539 | 0.000519 | 0.000499 | 0.000481 | 0.0 |
| 1994-01-12 | 0.181824 | 0.002845 | 0.002432 | 0.002124 | 0.001886 | 0.001695 | 0.001540 | 0.001410 | 0.286534 | 0.001207 | ... | 0.000843 | 0.084421 | 0.000766 | 0.000733 | 0.000702 | 0.166794 | 0.000648 | 0.000624 | 0.000601 | 0.0 |
| 1994-01-13 | 0.382995 | 0.002940 | 0.423047 | 0.082624 | 0.001949 | 0.001752 | 0.001591 | 0.001457 | 0.001344 | 0.001248 | ... | 0.000871 | 0.000830 | 0.000792 | 0.000757 | 0.000726 | 0.087974 | 0.000670 | 0.000645 | 0.000622 | 0.0 |
| 1994-01-13 | 0.161728 | 0.000729 | 0.000623 | 0.076846 | 0.000483 | 0.000434 | 0.000394 | 0.000361 | 0.149182 | 0.000309 | ... | 0.000216 | 0.000206 | 0.000196 | 0.000188 | 0.000180 | 0.000173 | 0.117813 | 0.000160 | 0.000154 | 0.0 |
| 1994-01-14 | 0.000182 | 0.000151 | 0.028138 | 0.000113 | 0.072985 | 0.000090 | 0.000082 | 0.266068 | 0.389534 | 0.000064 | ... | 0.000045 | 0.000043 | 0.000041 | 0.000039 | 0.000037 | 0.000036 | 0.006716 | 0.000033 | 0.000032 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2018-12-14 | 0.168223 | 0.000269 | 0.000230 | 0.737618 | 0.000179 | 0.000160 | 0.000146 | 0.000134 | 0.000123 | 0.000114 | ... | 0.000080 | 0.000076 | 0.011056 | 0.000069 | 0.038481 | 0.000064 | 0.000061 | 0.000059 | 0.035376 | 0.0 |
| 2018-12-14 | 0.000698 | 0.000580 | 0.030330 | 0.681720 | 0.000384 | 0.000345 | 0.000314 | 0.000287 | 0.000265 | 0.000246 | ... | 0.000172 | 0.000164 | 0.000156 | 0.000149 | 0.068615 | 0.000137 | 0.000132 | 0.000127 | 0.077063 | 0.0 |
| 2018-12-17 | 0.000037 | 0.000031 | 0.124490 | 0.000023 | 0.000020 | 0.000018 | 0.000017 | 0.000015 | 0.000014 | 0.000013 | ... | 0.009060 | 0.000009 | 0.000008 | 0.000008 | 0.005135 | 0.000007 | 0.000007 | 0.753522 | 0.065392 | 0.0 |
| 2018-12-19 | 0.040422 | 0.003601 | 0.000205 | 0.759449 | 0.000159 | 0.000143 | 0.000130 | 0.000119 | 0.023405 | 0.000102 | ... | 0.000071 | 0.000068 | 0.000065 | 0.070067 | 0.047990 | 0.000057 | 0.000055 | 0.000053 | 0.000051 | 0.0 |
| 2018-12-21 | 0.020200 | 0.000023 | 0.001905 | 0.000017 | 0.000015 | 0.000014 | 0.000012 | 0.032592 | 0.000010 | 0.000010 | ... | 0.001759 | 0.000006 | 0.001998 | 0.000006 | 0.011207 | 0.003687 | 0.000005 | 0.840280 | 0.040360 | 0.0 |
37690 rows × 25 columns
import matplotlib.pyplot as plt
plt.style.use('bmh')
fig,axs = plt.subplots(6,4,figsize = [20,15])
for ax,column in zip(axs.flat,evolution_df.groupby('Date').mean().columns):
ax.plot(evolution_df.resample('Y').mean()[column])
ax.set_title('Topic ' + str(column+1),{'fontsize':14})
plt.subplots_adjust(hspace=0.4)
plt.savefig('topic_trends.png',facecolor='white')
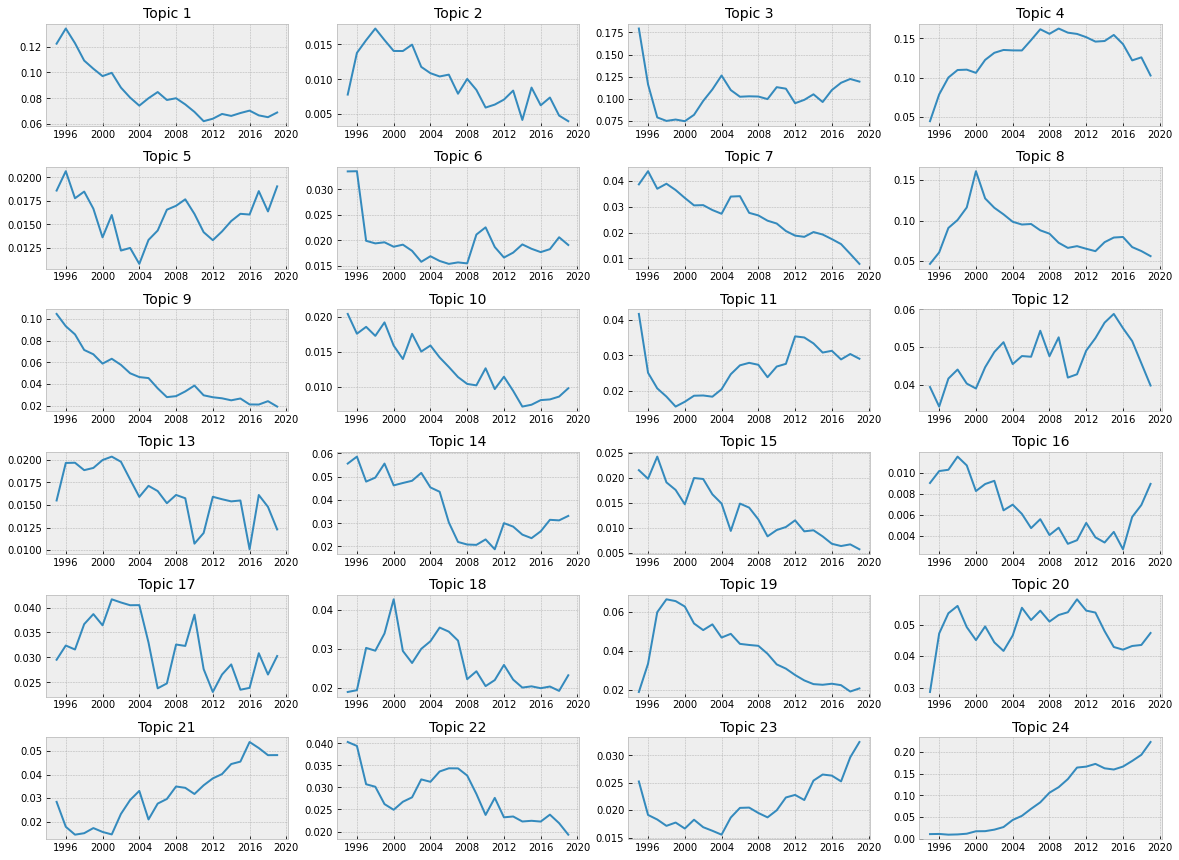
evolution_df.groupby('Date').mean()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||||||||||||||
| 1994-01-11 | 0.002672 | 0.084114 | 0.001908 | 0.001669 | 0.001484 | 0.001335 | 0.001214 | 0.001113 | 0.001027 | 0.000954 | ... | 0.000668 | 0.070999 | 0.000607 | 0.040693 | 0.000556 | 0.000534 | 0.000514 | 0.000495 | 0.000477 | 0.000460 |
| 1994-01-12 | 0.165192 | 0.002774 | 0.002378 | 0.002080 | 0.001849 | 0.001664 | 0.001513 | 0.001387 | 0.001280 | 0.328885 | ... | 0.000832 | 0.000793 | 0.000756 | 0.000724 | 0.140169 | 0.248372 | 0.000640 | 0.092614 | 0.000594 | 0.000574 |
| 1994-01-13 | 0.002147 | 0.001789 | 0.001533 | 0.171230 | 0.001193 | 0.077450 | 0.000976 | 0.000894 | 0.000826 | 0.090481 | ... | 0.000537 | 0.000511 | 0.000488 | 0.012837 | 0.123681 | 0.077247 | 0.000413 | 0.038453 | 0.000383 | 0.000370 |
| 1994-01-14 | 0.000176 | 0.000147 | 0.016850 | 0.000110 | 0.000098 | 0.000088 | 0.000080 | 0.000073 | 0.305317 | 0.333068 | ... | 0.074534 | 0.000042 | 0.000040 | 0.058617 | 0.000037 | 0.000035 | 0.210333 | 0.000033 | 0.000031 | 0.000030 |
| 1994-01-20 | 0.000602 | 0.000502 | 0.041115 | 0.000376 | 0.031761 | 0.000301 | 0.000274 | 0.000251 | 0.000232 | 0.047885 | ... | 0.000151 | 0.134882 | 0.000137 | 0.205165 | 0.000125 | 0.000120 | 0.000116 | 0.103733 | 0.000108 | 0.124254 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2018-12-13 | 0.000078 | 0.129760 | 0.000055 | 0.000049 | 0.000043 | 0.004215 | 0.003749 | 0.002766 | 0.000030 | 0.021995 | ... | 0.134767 | 0.000018 | 0.187314 | 0.000768 | 0.152157 | 0.127077 | 0.063852 | 0.000014 | 0.000014 | 0.005320 |
| 2018-12-14 | 0.013060 | 0.001920 | 0.047623 | 0.001671 | 0.017240 | 0.012425 | 0.181569 | 0.000960 | 0.079862 | 0.000823 | ... | 0.000576 | 0.012419 | 0.000524 | 0.000501 | 0.049364 | 0.523631 | 0.000935 | 0.000427 | 0.000411 | 0.000397 |
| 2018-12-17 | 0.013322 | 0.905966 | 0.000026 | 0.002329 | 0.000020 | 0.000018 | 0.014086 | 0.006846 | 0.000014 | 0.008798 | ... | 0.000009 | 0.000009 | 0.000008 | 0.000008 | 0.003804 | 0.009520 | 0.035143 | 0.000007 | 0.000006 | 0.000006 |
| 2018-12-19 | 0.039645 | 0.000234 | 0.000200 | 0.000175 | 0.137774 | 0.000140 | 0.039723 | 0.000117 | 0.000108 | 0.000100 | ... | 0.000070 | 0.022194 | 0.007625 | 0.066154 | 0.000058 | 0.664034 | 0.000054 | 0.000052 | 0.003400 | 0.000048 |
| 2018-12-21 | 0.766643 | 0.147026 | 0.000019 | 0.000017 | 0.000015 | 0.000013 | 0.000012 | 0.000916 | 0.000010 | 0.000009 | ... | 0.000007 | 0.000006 | 0.003149 | 0.000006 | 0.010862 | 0.004616 | 0.059489 | 0.003295 | 0.000005 | 0.000005 |
5448 rows × 25 columns
evolution_df
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||||||||||||||
| 1994-01-11 | 0.000000 | 0.000000 | 0.785467 | 0.090089 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.025628 | 0.000000 | 0.000000 | 0.000000 | 0.079328 |
| 1994-01-12 | 0.134804 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.311464 | 0.262941 | 0.000000 | 0.000000 | 0.177666 |
| 1994-01-13 | 0.000000 | 0.065354 | 0.731392 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.040434 | 0.000000 | 0.053730 |
| 1994-01-13 | 0.000000 | 0.000000 | 0.157713 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.0 | 0.478833 | 0.000000 | 0.0 | 0.106439 | 0.042836 | 0.000000 | 0.157657 | 0.000000 |
| 1994-01-14 | 0.000000 | 0.000000 | 0.000000 | 0.012322 | 0.227990 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.381352 | 0.000000 | 0.013187 | 0.029121 | 0.000000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2018-12-14 | 0.000000 | 0.000000 | 0.174175 | 0.760202 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.026959 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 2018-12-14 | 0.000000 | 0.000000 | 0.067577 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.574516 | 0.0 | 0.045159 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.024555 | 0.000000 | 0.226741 |
| 2018-12-17 | 0.890380 | 0.000000 | 0.015360 | 0.000000 | 0.026851 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.045834 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 2018-12-19 | 0.000000 | 0.000000 | 0.000000 | 0.054266 | 0.037535 | 0.0 | 0.0 | 0.505622 | 0.0 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.078784 | 0.0 | 0.047614 | 0.000000 | 0.124766 | 0.000000 | 0.122798 |
| 2018-12-21 | 0.862453 | 0.000000 | 0.000000 | 0.000000 | 0.099404 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.017382 |
37690 rows × 25 columns
import collections
files[0]
'19940111_10-Q_edgar_data_19704_0000019704-94-000001_1.txt'
sample_doc = open(source_dir+files[7000]).read().split('</Header>')[1]
tokens = gensim.utils.simple_preprocess(sample_doc)
red_tokens = [token for token in tokens if token not in stop_words]
collections.Counter(red_tokens).most_common()
doc = nlp(" ".join(red_tokens))
lemmas = [token.lemma_ for token in doc if token.pos_ in ['NOUN']]