3. Computer vision example - dogs and cats¶
For this example, we need to load the data ourselves that is somewhat laborious. We use image classification data from www.kaggle.com/c/dogs-vs-cats. Kaggle organises ML-competitions, and in this competition, the task is to distinguish dogs from cats in images.

First, we load some libraries that are needed to manipulate the image files.
import os,shutil
I have the original training data in the “original_data” folder (under the work folder). You can download the original data from www.kaggle.com/c/dogs-vs-cats.
files = os.listdir('./original_data')
The total number of dog and cat images is 25 000.
len(files)
25000
We do this training “by-the-book” by dividing the data to train, validation and test parts. The validation data is used to finetune the hyperparameters of a model. With separate validation data, we avoid using the hyperparameter optimisation wrongly to optimise the test data performance. Below is an example of a dataset-split that uses 3-fold cross-validation.
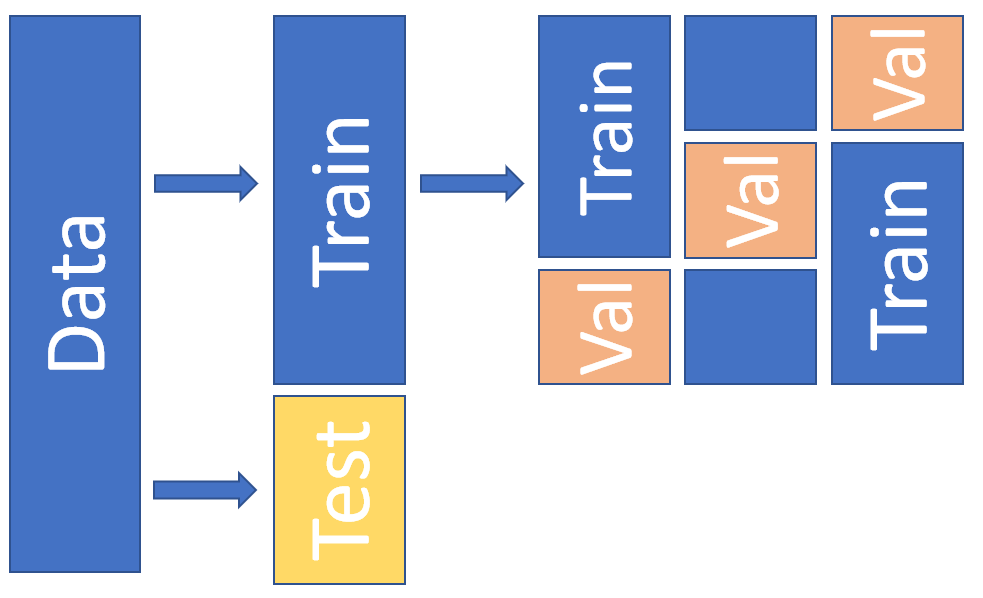
The following commands build different folders for the training, validation and test data.
os.mkdir('train')
os.mkdir('validation')
os.mkdir('test')
Under the training, validation and test -folders we make separate folders for the dog and cat pictures. This makes it much easier to use Keras data-generation function as it can automatically collect observations of different classes from different folders. os.path.join() -function makes it easy to build directory structures. You add the “parts” of the directory structure, and it will add automatically slashes when needed.
# Get the current work directory
base_dir = os.getcwd()
# Dogs
os.mkdir(os.path.join(base_dir,'train','dogs'))
os.mkdir(os.path.join(base_dir,'validation','dogs'))
os.mkdir(os.path.join(base_dir,'test','dogs'))
# Cats
os.mkdir(os.path.join(base_dir,'train','cats'))
os.mkdir(os.path.join(base_dir,'validation','cats'))
os.mkdir(os.path.join(base_dir,'test','cats'))
Next, we copy the files to correct folders. We use only part of the data to speed up calculations: 3000 images for the training, 1000 images for the validation and 1000 images for the testing. The first command in each cell constructs a list of correct filenames. It uses Python’s list comprehension, that is a great feature in Python.
Let’s analyse the first one (fnames = [‘dog.{}.jpg’.format(i) for i in range(1500)]):
When we put a for loop inside square brackets, Python will generate a list that has the “rounds” of a loop as values in the list.
‘dog.{}.jpg’.format(i) - This is the part that will be repeated in the list so that the curly brackets are replaced by the value of i.
for i in range(1500) - This will tell what values are inserted in i. range(1500) just means values from 0 to 1500.
More information about list comprehension can be found from https://docs.python.org/3/tutorial/datastructures.html (section 5.1.3)
# Train dogs
fnames = ['dog.{}.jpg'.format(i) for i in range(1500)]
for file in fnames:
src = os.path.join(base_dir,'original_data',file)
dst = os.path.join(base_dir,'train','dogs',file)
shutil.copyfile(src,dst)
# Validation dogs
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for file in fnames:
src = os.path.join(base_dir,'original_data',file)
dst = os.path.join(base_dir,'validation','dogs',file)
shutil.copyfile(src,dst)
# Test dogs
fnames = ['dog.{}.jpg'.format(i) for i in range(2000,2500)]
for file in fnames:
src = os.path.join(base_dir,'original_data',file)
dst = os.path.join(base_dir,'test','dogs',file)
shutil.copyfile(src,dst)
# Train cats
fnames = ['cat.{}.jpg'.format(i) for i in range(1500)]
for file in fnames:
src = os.path.join(base_dir,'original_data',file)
dst = os.path.join(base_dir,'train','cats',file)
shutil.copyfile(src,dst)
# Validation cats
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for file in fnames:
src = os.path.join(base_dir,'original_data',file)
dst = os.path.join(base_dir,'validation','cats',file)
shutil.copyfile(src,dst)
# Test cats
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for file in fnames:
src = os.path.join(base_dir,'original_data',file)
dst = os.path.join(base_dir,'test','cats',file)
shutil.copyfile(src,dst)
Next, we check that everything went as planned. The dog folders should have 1500,500 and 500 images and similarly to the cat folders.
# Check the dog directories
print(len(os.listdir(os.path.join(base_dir,'train','dogs'))))
print(len(os.listdir(os.path.join(base_dir,'validation','dogs'))))
print(len(os.listdir(os.path.join(base_dir,'test','dogs'))))
1500
500
500
# Check the cat directories
print(len(os.listdir(os.path.join(base_dir,'train','cats'))))
print(len(os.listdir(os.path.join(base_dir,'validation','cats'))))
print(len(os.listdir(os.path.join(base_dir,'test','cats'))))
1500
500
500
3.1. Simple CNN model¶
As our preliminary model, we test a basic CNN model with four convolutional layers and four max-pooling layers followed by two dense layers with 12544 (flatten) and 512 neurons. The output layer has one neuron with a sigmoid activation function. So, the output is a prediction for one of the two classes.
First, we need the layers and models -modules from Keras.
from tensorflow.keras import layers
from tensorflow.keras import models
Next, we define a sequential model and add layers using the add()-function.
model = models.Sequential()
The input images to the network are 150x150 pixel RGB images. The size of the convolution-filter is 3x3, and the layer produces 32 feature maps. The ReLU activation function is the common choice with CNNs (and many other neural network types).
model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3)))
A max-pooling layer with a 2x2 window.
model.add(layers.MaxPooling2D((2, 2)))
Notice how the number of feature maps is increasing.
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
Overall, we have almost 7 million parameters in our model, which is way too much for a training set with 3000 images. The model will overfit as we will soon see from the results.
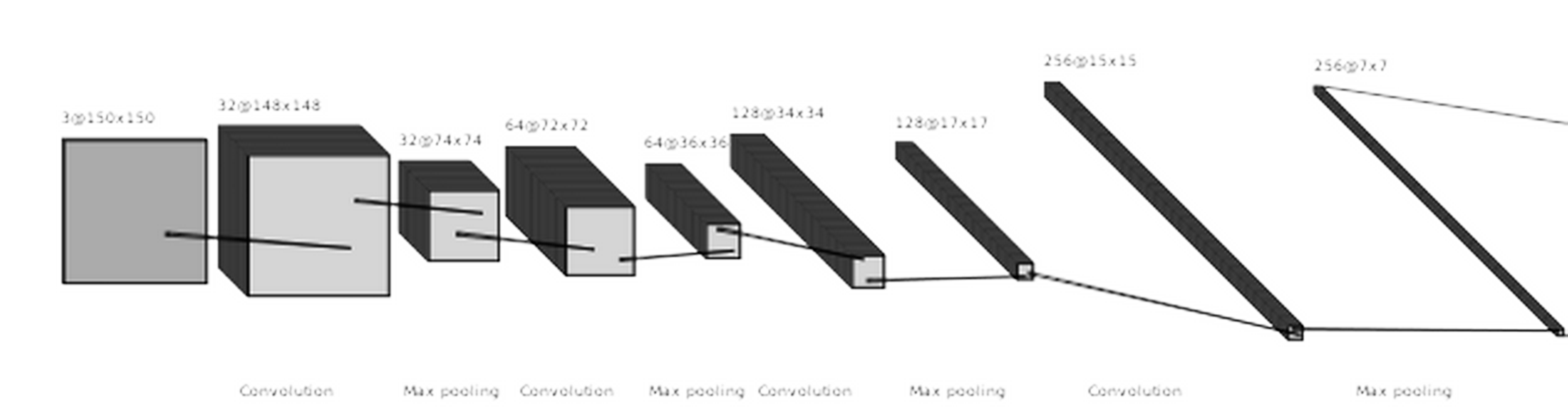
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 15, 15, 256) 295168
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 7, 7, 256) 0
_________________________________________________________________
flatten (Flatten) (None, 12544) 0
_________________________________________________________________
dense (Dense) (None, 512) 6423040
_________________________________________________________________
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 6,811,969
Trainable params: 6,811,969
Non-trainable params: 0
_________________________________________________________________
from tensorflow.keras import optimizers
Next, we compile the model. Because we have now two classes, “binary_crossentropy” is the correct loss_function. There are many gradient descent optimisers available, but usually, RMSprop works very well. More information about RMSprop can be found here: https://keras.io/api/optimizers/rmsprop/.
We measure performance with the accuracy metric.
model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(),metrics=['acc'])
To get images from a folder to a CNN model can be a very tedious task. Luckily, Keras has functions that make our job much more straightforward.
ImageDataGenerator is a Python generator that can be used to transform images from a folder to tensors that can be fed to a neural network model.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
We scale the pixel values from 0-255 to 0-1. Remember: neural networks like small values.
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)
We change the size of the images to 150 x 150 and collect them in 25 batches. Basically, we feed (25,150,150,3)-tensors to the model. As you can see, the function automatically recognises two different classes. It is because we placed the cat and dog images to two different folders. We have to make separate generators for the training data and the validation data.
train_generator = train_datagen.flow_from_directory(os.path.join(base_dir,'train'),
target_size=(150, 150),
batch_size=25,
class_mode='binary')
Found 3000 images belonging to 2 classes.
validation_generator = train_datagen.flow_from_directory(os.path.join(base_dir,'validation'),
target_size=(150, 150),
batch_size=25,
class_mode='binary')
Found 1000 images belonging to 2 classes.
We use a little bit longer training with 30 epochs. Instead of input data, we now give the generators to the model. Also, we separately define the validation generator and validation testing steps. With 25 image batches and 120 steps per epoch, we go through all the 3000 images. To history, we save the training progress details.
history = model.fit(train_generator,
steps_per_epoch=120,
epochs=30,
validation_data=validation_generator,
validation_steps=40)
Epoch 1/30
120/120 [==============================] - 8s 64ms/step - loss: 0.8037 - acc: 0.5173 - val_loss: 0.6853 - val_acc: 0.5300
Epoch 2/30
120/120 [==============================] - 7s 58ms/step - loss: 0.6898 - acc: 0.5633 - val_loss: 0.6772 - val_acc: 0.5510
Epoch 3/30
120/120 [==============================] - 7s 59ms/step - loss: 0.6474 - acc: 0.6457 - val_loss: 0.6194 - val_acc: 0.6460
Epoch 4/30
120/120 [==============================] - 7s 59ms/step - loss: 0.5763 - acc: 0.7100 - val_loss: 0.6237 - val_acc: 0.6950
Epoch 5/30
120/120 [==============================] - 8s 65ms/step - loss: 0.5350 - acc: 0.7443 - val_loss: 0.5508 - val_acc: 0.7220
Epoch 6/30
120/120 [==============================] - 8s 64ms/step - loss: 0.4642 - acc: 0.7803 - val_loss: 0.6734 - val_acc: 0.6840
Epoch 7/30
120/120 [==============================] - 8s 64ms/step - loss: 0.4025 - acc: 0.8160 - val_loss: 0.6532 - val_acc: 0.6730
Epoch 8/30
120/120 [==============================] - 8s 64ms/step - loss: 0.3565 - acc: 0.8507 - val_loss: 0.5980 - val_acc: 0.7160
Epoch 9/30
120/120 [==============================] - 8s 64ms/step - loss: 0.2777 - acc: 0.8797 - val_loss: 0.6849 - val_acc: 0.7250
Epoch 10/30
120/120 [==============================] - 8s 65ms/step - loss: 0.2132 - acc: 0.9200 - val_loss: 0.7644 - val_acc: 0.7490
Epoch 11/30
120/120 [==============================] - 8s 66ms/step - loss: 0.1616 - acc: 0.9383 - val_loss: 0.9507 - val_acc: 0.7600
Epoch 12/30
120/120 [==============================] - 8s 64ms/step - loss: 0.1280 - acc: 0.9550 - val_loss: 0.9920 - val_acc: 0.7580
Epoch 13/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0928 - acc: 0.9647 - val_loss: 1.1380 - val_acc: 0.7380
Epoch 14/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0865 - acc: 0.9703 - val_loss: 1.6679 - val_acc: 0.7370
Epoch 15/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0967 - acc: 0.9770 - val_loss: 1.6271 - val_acc: 0.7500
Epoch 16/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0502 - acc: 0.9863 - val_loss: 2.3183 - val_acc: 0.7160
Epoch 17/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0916 - acc: 0.9740 - val_loss: 1.4569 - val_acc: 0.7260
Epoch 18/30
120/120 [==============================] - 8s 64ms/step - loss: 0.0473 - acc: 0.9863 - val_loss: 2.0985 - val_acc: 0.7450
Epoch 19/30
120/120 [==============================] - 8s 66ms/step - loss: 0.0380 - acc: 0.9880 - val_loss: 1.9232 - val_acc: 0.7560
Epoch 20/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0704 - acc: 0.9800 - val_loss: 1.5092 - val_acc: 0.7380
Epoch 21/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0382 - acc: 0.9873 - val_loss: 2.3736 - val_acc: 0.7380
Epoch 22/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0708 - acc: 0.9817 - val_loss: 2.1743 - val_acc: 0.7080
Epoch 23/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0513 - acc: 0.9880 - val_loss: 3.1436 - val_acc: 0.6800
Epoch 24/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0701 - acc: 0.9817 - val_loss: 1.8264 - val_acc: 0.7290
Epoch 25/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0424 - acc: 0.9890 - val_loss: 2.7340 - val_acc: 0.7300
Epoch 26/30
120/120 [==============================] - 8s 67ms/step - loss: 0.0512 - acc: 0.9920 - val_loss: 3.3945 - val_acc: 0.7280
Epoch 27/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0926 - acc: 0.9843 - val_loss: 3.0478 - val_acc: 0.7170
Epoch 28/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0337 - acc: 0.9927 - val_loss: 3.3952 - val_acc: 0.7360
Epoch 29/30
120/120 [==============================] - 8s 66ms/step - loss: 0.0480 - acc: 0.9913 - val_loss: 3.2892 - val_acc: 0.7320
Epoch 30/30
120/120 [==============================] - 8s 65ms/step - loss: 0.0711 - acc: 0.9873 - val_loss: 2.3569 - val_acc: 0.7020
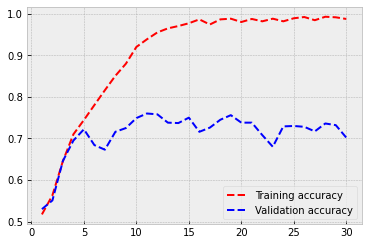
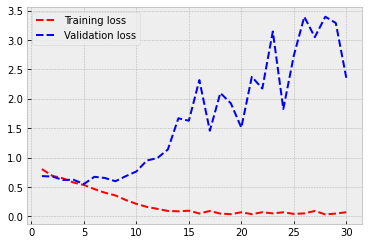
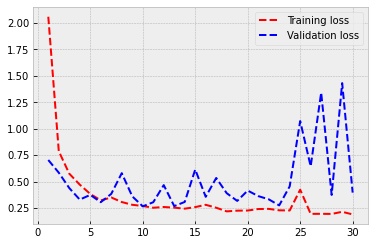
Let’s check how did it go. In a typical overfitting situation, training accuracy quickly rises to almost 1.0 and validation accuracy stalls to a much lower level. This is also the case here. The training accuracy is 0.984, and the validation accuracy is around 0.72. But still, not that bad! The model recognises cats and dogs correctly from the images 72 % of the time.

import matplotlib.pyplot as plt # Load plotting libraries
plt.style.use('bmh') # bmh-style is usually nice
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'r--', label='Training accuracy')
plt.plot(epochs, val_acc, 'b--', label='Validation accuracy')
plt.legend() # Matplotlib will automatically position the legend in a best possible way.
plt.figure() # This is needed to make two separate figures for loss and accuracy.
plt.plot(epochs, loss, 'r--', label='Training loss')
plt.plot(epochs, val_loss, 'b--', label='Validation loss')
plt.legend()
plt.show()
3.2. Augmentation and regularisation¶
Let’s try to improve our model. Augmentation is a common approach to “increase” the amount of data. The idea of augmentation is to transform images slightly every time they are fed to the model. Thus, we are trying to create new information to the model to train on. However, we are not truly creating new information. Nevertheless, augmentation has proven to be an efficient way to improve results.
Image transformation can be implemented to the ImageDataGenerator()-function. There are many parameters that can be used to transform images. More information: keras.io/api/preprocessing/image/
datagen = ImageDataGenerator(rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
Let’s check what kind of images we are analysing.
# Image -module to view images
from tensorflow.keras.preprocessing import image
# We pick the 16th image from the train/dogs -folder.
img_path = os.path.join(base_dir,'train','dogs',os.listdir(os.path.join(base_dir,'train','dogs'))[16])
sample_image = image.load_img(img_path, target_size=(150, 150))
Below is an example image from the original dataset. The sixteenth image in our list.
sample_image

To use the Imagedatagenerator’s flow()-function, we need to transform our image to a numpy-array.
sample_image_np = image.img_to_array(sample_image)
sample_image_np = sample_image_np.reshape((1,) + sample_image_np.shape)
The following code transforms images using ImageDataGenerator() and plots eight examples. As you can see, they are slightly altered images that are very close to the original image.
fig, axs = plt.subplots(2,4,figsize=(14,6),squeeze=True)
i=0
for ax,transform in zip(axs.flat,datagen.flow(sample_image_np, batch_size=1)):
ax.imshow(image.array_to_img(transform[0]))
i+=1
if i%8==0:
break

Next, we define the model. Alongside augmentation, we add regularisation to the model with a dropout-layer. The Dropout layer randomly sets input units to 0 with a frequency of rate (0.5 below) at each step during training time, which helps prevent overfitting. Inputs not set to 0 are scaled up by 1/(1 - rate) such that the sum over all inputs is unchanged.
We build our sequential model using add()-functions. The only difference, when compared to the previous model, is the dropout-layer after the flatten-layer (and the augmentation).
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
The dropout layer does not change the number of parameters. It is exactly the same as in the previous model.
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 15, 15, 256) 295168
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 7, 7, 256) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 12544) 0
_________________________________________________________________
dropout (Dropout) (None, 12544) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 6423040
_________________________________________________________________
dense_3 (Dense) (None, 1) 513
=================================================================
Total params: 6,811,969
Trainable params: 6,811,969
Non-trainable params: 0
_________________________________________________________________
The compile-step is not changed.
model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(),metrics=['acc'])
We create the augmentation-enabled generators. Remember that the validation dataset should not be augmented!
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen = ImageDataGenerator(rescale=1./255)
The same dataset of 3000 training images and 1000 validation images.
train_generator = train_datagen.flow_from_directory(os.path.join(base_dir,'train'),
target_size=(150, 150),
batch_size=25,
class_mode='binary')
Found 3000 images belonging to 2 classes.
validation_generator = validation_datagen.flow_from_directory(os.path.join(base_dir,'validation'),
target_size=(150, 150),
batch_size=25,
class_mode='binary')
Found 1000 images belonging to 2 classes.
Otherwise, the parameters to the model.fit() are the same as in the previous model, but we train the model a little bit longer. This is because regularisation slows down training.
history = model.fit(train_generator,
steps_per_epoch=120,
epochs=50,
validation_data=validation_generator,
validation_steps=40)
Epoch 1/50
120/120 [==============================] - 18s 153ms/step - loss: 0.7524 - acc: 0.5110 - val_loss: 0.6905 - val_acc: 0.5100
Epoch 2/50
120/120 [==============================] - 18s 152ms/step - loss: 0.6992 - acc: 0.5327 - val_loss: 0.6872 - val_acc: 0.5450
Epoch 3/50
120/120 [==============================] - 19s 157ms/step - loss: 0.7043 - acc: 0.5717 - val_loss: 0.6659 - val_acc: 0.5820
Epoch 4/50
120/120 [==============================] - 19s 162ms/step - loss: 0.6608 - acc: 0.6097 - val_loss: 0.6433 - val_acc: 0.6250
Epoch 5/50
120/120 [==============================] - 19s 160ms/step - loss: 0.6592 - acc: 0.6287 - val_loss: 0.6360 - val_acc: 0.6190
Epoch 6/50
120/120 [==============================] - 19s 162ms/step - loss: 0.6467 - acc: 0.6387 - val_loss: 0.6098 - val_acc: 0.6700
Epoch 7/50
120/120 [==============================] - 19s 161ms/step - loss: 0.6140 - acc: 0.6640 - val_loss: 0.6285 - val_acc: 0.6560
Epoch 8/50
120/120 [==============================] - 19s 160ms/step - loss: 0.6148 - acc: 0.6713 - val_loss: 0.5965 - val_acc: 0.6760
Epoch 9/50
120/120 [==============================] - 19s 161ms/step - loss: 0.6044 - acc: 0.6677 - val_loss: 0.6312 - val_acc: 0.6530
Epoch 10/50
120/120 [==============================] - 19s 162ms/step - loss: 0.6167 - acc: 0.6860 - val_loss: 0.6247 - val_acc: 0.6620
Epoch 11/50
120/120 [==============================] - 19s 161ms/step - loss: 0.6337 - acc: 0.6857 - val_loss: 0.5864 - val_acc: 0.6860
Epoch 12/50
120/120 [==============================] - 19s 160ms/step - loss: 0.5689 - acc: 0.7060 - val_loss: 0.6638 - val_acc: 0.6520
Epoch 13/50
120/120 [==============================] - 20s 163ms/step - loss: 0.5776 - acc: 0.7070 - val_loss: 0.5554 - val_acc: 0.7280
Epoch 14/50
120/120 [==============================] - 19s 161ms/step - loss: 0.5775 - acc: 0.7030 - val_loss: 0.5869 - val_acc: 0.6860
Epoch 15/50
120/120 [==============================] - 19s 161ms/step - loss: 0.5573 - acc: 0.7127 - val_loss: 0.5685 - val_acc: 0.7090
Epoch 16/50
120/120 [==============================] - 20s 164ms/step - loss: 0.5563 - acc: 0.7140 - val_loss: 0.5542 - val_acc: 0.7220
Epoch 17/50
120/120 [==============================] - 19s 159ms/step - loss: 0.5526 - acc: 0.7207 - val_loss: 0.5607 - val_acc: 0.7310
Epoch 18/50
120/120 [==============================] - 19s 158ms/step - loss: 0.5331 - acc: 0.7397 - val_loss: 0.5880 - val_acc: 0.6900
Epoch 19/50
120/120 [==============================] - 19s 160ms/step - loss: 0.5311 - acc: 0.7400 - val_loss: 0.6715 - val_acc: 0.6770
Epoch 20/50
120/120 [==============================] - 19s 159ms/step - loss: 0.5353 - acc: 0.7407 - val_loss: 0.5568 - val_acc: 0.7080
Epoch 21/50
120/120 [==============================] - 19s 158ms/step - loss: 0.5279 - acc: 0.7433 - val_loss: 0.5740 - val_acc: 0.7240
Epoch 22/50
120/120 [==============================] - 19s 160ms/step - loss: 0.5129 - acc: 0.7510 - val_loss: 0.6443 - val_acc: 0.6780
Epoch 23/50
120/120 [==============================] - 19s 158ms/step - loss: 0.5084 - acc: 0.7610 - val_loss: 0.5440 - val_acc: 0.7360
Epoch 24/50
120/120 [==============================] - 19s 158ms/step - loss: 0.5147 - acc: 0.7480 - val_loss: 0.6003 - val_acc: 0.7200
Epoch 25/50
120/120 [==============================] - 19s 160ms/step - loss: 0.5177 - acc: 0.7517 - val_loss: 0.4973 - val_acc: 0.7660
Epoch 26/50
120/120 [==============================] - 19s 157ms/step - loss: 0.5178 - acc: 0.7533 - val_loss: 0.5137 - val_acc: 0.7610
Epoch 27/50
120/120 [==============================] - 19s 158ms/step - loss: 0.5065 - acc: 0.7533 - val_loss: 0.5577 - val_acc: 0.7340
Epoch 28/50
120/120 [==============================] - 19s 160ms/step - loss: 0.5128 - acc: 0.7587 - val_loss: 0.5201 - val_acc: 0.7470
Epoch 29/50
120/120 [==============================] - 19s 159ms/step - loss: 0.4847 - acc: 0.7730 - val_loss: 0.6457 - val_acc: 0.7210
Epoch 30/50
120/120 [==============================] - 19s 158ms/step - loss: 0.5024 - acc: 0.7703 - val_loss: 0.5697 - val_acc: 0.7130
Epoch 31/50
120/120 [==============================] - 19s 160ms/step - loss: 0.4911 - acc: 0.7683 - val_loss: 0.5030 - val_acc: 0.7730
Epoch 32/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4957 - acc: 0.7703 - val_loss: 0.5170 - val_acc: 0.7540
Epoch 33/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4915 - acc: 0.7757 - val_loss: 0.5578 - val_acc: 0.7350
Epoch 34/50
120/120 [==============================] - 19s 159ms/step - loss: 0.4798 - acc: 0.7687 - val_loss: 0.4873 - val_acc: 0.7590
Epoch 35/50
120/120 [==============================] - 19s 159ms/step - loss: 0.4715 - acc: 0.7867 - val_loss: 0.5207 - val_acc: 0.7440
Epoch 36/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4877 - acc: 0.7830 - val_loss: 0.9541 - val_acc: 0.6310
Epoch 37/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4921 - acc: 0.7700 - val_loss: 0.4825 - val_acc: 0.7630
Epoch 38/50
120/120 [==============================] - 19s 159ms/step - loss: 0.4724 - acc: 0.7873 - val_loss: 0.5338 - val_acc: 0.7670
Epoch 39/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4784 - acc: 0.7787 - val_loss: 0.4914 - val_acc: 0.7790
Epoch 40/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4831 - acc: 0.7737 - val_loss: 0.4850 - val_acc: 0.7740
Epoch 41/50
120/120 [==============================] - 19s 159ms/step - loss: 0.4592 - acc: 0.7920 - val_loss: 1.8141 - val_acc: 0.6280
Epoch 42/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4649 - acc: 0.7977 - val_loss: 0.6301 - val_acc: 0.7470
Epoch 43/50
120/120 [==============================] - 19s 159ms/step - loss: 0.4710 - acc: 0.7840 - val_loss: 0.4698 - val_acc: 0.7900
Epoch 44/50
120/120 [==============================] - 19s 160ms/step - loss: 0.4532 - acc: 0.8013 - val_loss: 0.7657 - val_acc: 0.7160
Epoch 45/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4692 - acc: 0.7877 - val_loss: 0.5176 - val_acc: 0.7510
Epoch 46/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4677 - acc: 0.7980 - val_loss: 0.5151 - val_acc: 0.7440
Epoch 47/50
120/120 [==============================] - 19s 160ms/step - loss: 0.4568 - acc: 0.8047 - val_loss: 0.4905 - val_acc: 0.7680
Epoch 48/50
120/120 [==============================] - 19s 159ms/step - loss: 0.4549 - acc: 0.7977 - val_loss: 0.5255 - val_acc: 0.7300
Epoch 49/50
120/120 [==============================] - 19s 158ms/step - loss: 0.4412 - acc: 0.8037 - val_loss: 0.6317 - val_acc: 0.7810
Epoch 50/50
120/120 [==============================] - 19s 160ms/step - loss: 0.4630 - acc: 0.7927 - val_loss: 0.4893 - val_acc: 0.7710
As you can see from the following figure, overfitting has almost disappeared. The training and validation accuracy stay approximately at the same level through the training. The performance is also somewhat better. Now we achieve a validation accuracy of 0.77.
plt.style.use('bmh')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'r--', label='Training acc')
plt.plot(epochs, val_acc, 'b--', label='Validation acc')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'r--', label='Training loss')
plt.plot(epochs, val_loss, 'b--', label='Validation loss')
plt.legend()
plt.show()
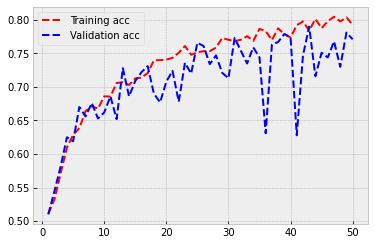
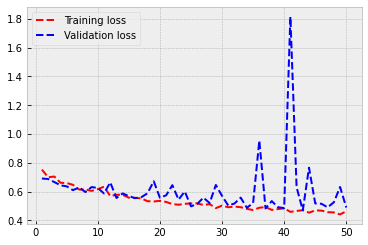
3.3. Pre-trained model¶
Next thing that we could try is to use a pre-trained model that has its parameters already optimised using some other dataset. Usually, CNNs related to computer vision are pre-trained using Imagenet data (http://www.image-net.org/). It is a vast collection of labelled images.
We add our own layers after the pre-trained architecture. As our pre-trained model, we use VGG16
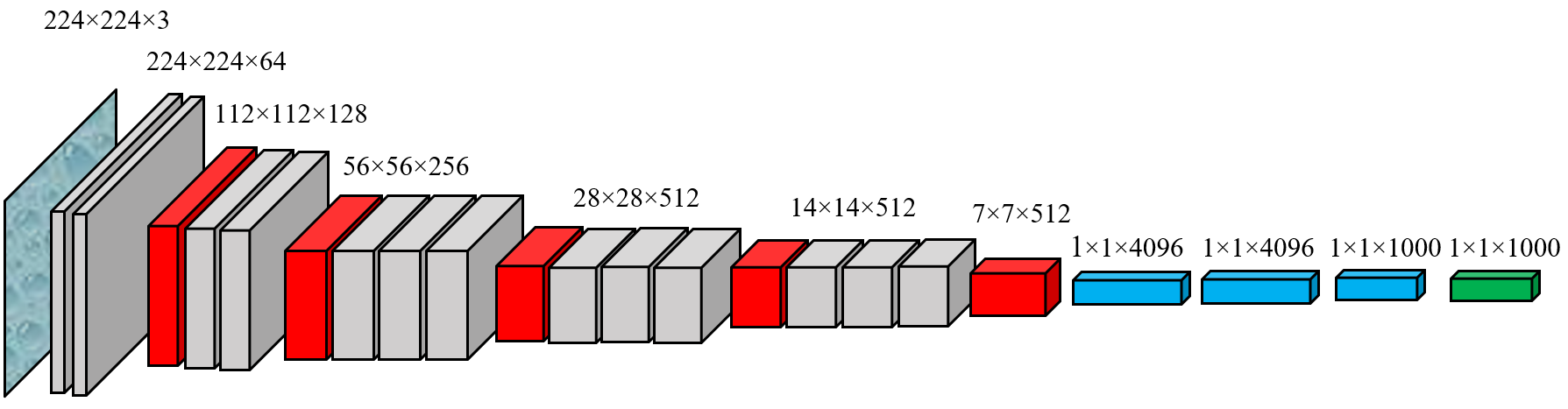
VGG16 is included in the keras.applications -module
from tensorflow.keras.applications import VGG16
When we load the VGG16 model, we need to set weights=imagenet to get pre-trained parameter weights. include_top=False removes the output layer with 1000 neurons. We want our output layer to have only one neuron (prediction for dog/cat).
pretrained_base = VGG16(weights='imagenet',include_top=False,input_shape=(150, 150, 3))
VGG16 has 14.7 million parameters without the last layer. It also has two or three convolutional layers in a row. Our previous models were switching between a convolutional layer and a max-pooling layer.
pretrained_base.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
model = models.Sequential()
When we construct the model, we add the pre-trained VGG16-base first. Then follows a 256-neuron Dense-layer and a one-neuron output layer.
model.add(pretrained_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
Overall, our model has almost 17 million parameters. However, we will lock the pre-trained VGG16 base, which will decrease the number of trainable parameters significantly.
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Model) (None, 4, 4, 512) 14714688
_________________________________________________________________
flatten_3 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_6 (Dense) (None, 256) 2097408
_________________________________________________________________
dense_7 (Dense) (None, 1) 257
=================================================================
Total params: 16,812,353
Trainable params: 2,097,665
Non-trainable params: 14,714,688
_________________________________________________________________
We want to use the pretrained Imagenet-weights, so, we lock the weights of the VGG16 -part.
pretrained_base.trainable = False
Now there is “only” two million trainable parameters.
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Model) (None, 4, 4, 512) 14714688
_________________________________________________________________
flatten_3 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_6 (Dense) (None, 256) 2097408
_________________________________________________________________
dense_7 (Dense) (None, 1) 257
=================================================================
Total params: 16,812,353
Trainable params: 2,097,665
Non-trainable params: 14,714,688
_________________________________________________________________
Again, we use the augmentation of the training dataset.
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(os.path.join(base_dir,'train'),
target_size=(150, 150),
batch_size=25,
class_mode='binary')
Found 3000 images belonging to 2 classes.
validation_generator = validation_datagen.flow_from_directory(os.path.join(base_dir,'validation'),
target_size=(150, 150),
batch_size=25,
class_mode='binary')
Found 1000 images belonging to 2 classes.
Compile- and fit-steps do not have anything new.
model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(),metrics=['acc'])
history = model.fit(train_generator,
steps_per_epoch=120,
epochs=30,
validation_data=validation_generator,
validation_steps=40)
Epoch 1/30
120/120 [==============================] - 19s 154ms/step - loss: 0.7037 - acc: 0.6993 - val_loss: 0.8838 - val_acc: 0.6290
Epoch 2/30
120/120 [==============================] - 19s 156ms/step - loss: 0.4647 - acc: 0.7800 - val_loss: 0.3712 - val_acc: 0.8330
Epoch 3/30
120/120 [==============================] - 20s 167ms/step - loss: 0.3892 - acc: 0.8227 - val_loss: 0.3719 - val_acc: 0.8110
Epoch 4/30
120/120 [==============================] - 20s 167ms/step - loss: 0.4137 - acc: 0.8117 - val_loss: 0.3698 - val_acc: 0.8300
Epoch 5/30
120/120 [==============================] - 20s 168ms/step - loss: 0.3779 - acc: 0.8307 - val_loss: 0.4457 - val_acc: 0.8180
Epoch 6/30
120/120 [==============================] - 21s 171ms/step - loss: 0.3472 - acc: 0.8437 - val_loss: 0.3521 - val_acc: 0.8320
Epoch 7/30
120/120 [==============================] - 20s 169ms/step - loss: 0.3545 - acc: 0.8357 - val_loss: 0.3581 - val_acc: 0.8360
Epoch 8/30
120/120 [==============================] - 20s 168ms/step - loss: 0.3390 - acc: 0.8453 - val_loss: 0.3456 - val_acc: 0.8430
Epoch 9/30
120/120 [==============================] - 20s 170ms/step - loss: 0.3302 - acc: 0.8607 - val_loss: 0.3451 - val_acc: 0.8640
Epoch 10/30
120/120 [==============================] - 20s 168ms/step - loss: 0.3169 - acc: 0.8567 - val_loss: 0.3653 - val_acc: 0.8270
Epoch 11/30
120/120 [==============================] - 20s 167ms/step - loss: 0.3209 - acc: 0.8617 - val_loss: 0.3418 - val_acc: 0.8500
Epoch 12/30
120/120 [==============================] - 20s 169ms/step - loss: 0.3075 - acc: 0.8660 - val_loss: 0.3342 - val_acc: 0.8540
Epoch 13/30
120/120 [==============================] - 20s 168ms/step - loss: 0.3122 - acc: 0.8637 - val_loss: 0.3647 - val_acc: 0.8530
Epoch 14/30
120/120 [==============================] - 20s 168ms/step - loss: 0.3056 - acc: 0.8623 - val_loss: 0.4162 - val_acc: 0.8330
Epoch 15/30
120/120 [==============================] - 20s 170ms/step - loss: 0.2856 - acc: 0.8760 - val_loss: 0.3395 - val_acc: 0.8390
Epoch 16/30
120/120 [==============================] - 20s 168ms/step - loss: 0.2912 - acc: 0.8683 - val_loss: 0.3573 - val_acc: 0.8460
Epoch 17/30
120/120 [==============================] - 20s 168ms/step - loss: 0.2934 - acc: 0.8697 - val_loss: 0.3263 - val_acc: 0.8560
Epoch 18/30
120/120 [==============================] - 20s 170ms/step - loss: 0.2972 - acc: 0.8683 - val_loss: 0.3513 - val_acc: 0.8420
Epoch 19/30
120/120 [==============================] - 20s 168ms/step - loss: 0.2790 - acc: 0.8740 - val_loss: 0.3476 - val_acc: 0.8560
Epoch 20/30
120/120 [==============================] - 20s 168ms/step - loss: 0.2913 - acc: 0.8753 - val_loss: 0.3335 - val_acc: 0.8610
Epoch 21/30
120/120 [==============================] - 20s 170ms/step - loss: 0.2797 - acc: 0.8823 - val_loss: 0.4258 - val_acc: 0.8370
Epoch 22/30
120/120 [==============================] - 20s 169ms/step - loss: 0.2730 - acc: 0.8877 - val_loss: 0.3817 - val_acc: 0.8450
Epoch 23/30
120/120 [==============================] - 20s 165ms/step - loss: 0.2684 - acc: 0.8850 - val_loss: 0.3305 - val_acc: 0.8550
Epoch 24/30
120/120 [==============================] - 20s 167ms/step - loss: 0.2796 - acc: 0.8810 - val_loss: 0.4782 - val_acc: 0.8010
Epoch 25/30
120/120 [==============================] - 20s 165ms/step - loss: 0.2721 - acc: 0.8807 - val_loss: 0.4001 - val_acc: 0.8270
Epoch 26/30
120/120 [==============================] - 20s 166ms/step - loss: 0.2876 - acc: 0.8803 - val_loss: 0.3274 - val_acc: 0.8610
Epoch 27/30
120/120 [==============================] - 20s 166ms/step - loss: 0.2664 - acc: 0.8827 - val_loss: 0.3418 - val_acc: 0.8510
Epoch 28/30
120/120 [==============================] - 20s 165ms/step - loss: 0.2654 - acc: 0.8920 - val_loss: 0.3860 - val_acc: 0.8370
Epoch 29/30
120/120 [==============================] - 20s 165ms/step - loss: 0.2539 - acc: 0.8907 - val_loss: 0.3810 - val_acc: 0.8560
Epoch 30/30
120/120 [==============================] - 20s 167ms/step - loss: 0.2659 - acc: 0.8867 - val_loss: 0.3408 - val_acc: 0.8620
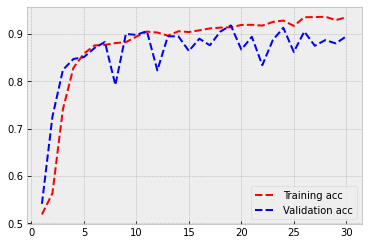
As you can see from the plots below, there is a small overfitting issue. The difference between the training accuracy and the validation accuracy increases slowly. However, the performance is excellent! Now our model can separate dogs from cats correctly 85 % of the time.
plt.style.use('bmh')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'r--', label='Training acc')
plt.plot(epochs, val_acc, 'b--', label='Validation acc')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'r--', label='Training loss')
plt.plot(epochs, val_loss, 'b--', label='Validation loss')
plt.legend()
plt.show()
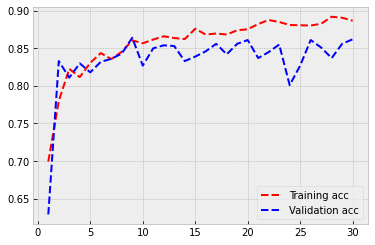
3.4. Fine tuning¶
There is still (at least) one thing that we can do to improve our model. We can finetune our pre-trained VGG16 model by opening part of its’ weights. As our VGG16 is now optimised for Imagenet data, the weights have information about features that are useful for many different types of images. By opening the last few layers of the model, we allow it to finetune those weights to features that are useful in separating dogs from cats in images.
First, we need to make our VGG16 model trainable again.
pretrained_base.trainable = True
Here is the summary of the VGG16 model again.
pretrained_base.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
Let’ lock everything else, but leave the layers of block5 to be finetuned by our dogs/cats images. The following code will go through the VGG16 structure, lock everything until ‘block4_pool’ and leave layers after that trainable.
set_trainable = False
for layer in pretrained_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
There are over 9 million trainable parameters, which can probably cause overfitting, but let’s see.
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Model) (None, 4, 4, 512) 14714688
_________________________________________________________________
flatten_3 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_6 (Dense) (None, 256) 2097408
_________________________________________________________________
dense_7 (Dense) (None, 1) 257
=================================================================
Total params: 16,812,353
Trainable params: 9,177,089
Non-trainable params: 7,635,264
_________________________________________________________________
model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(),metrics=['acc'])
history = model.fit(train_generator,
steps_per_epoch=120,
epochs=30,
validation_data=validation_generator,
validation_steps=40)
Epoch 1/30
120/120 [==============================] - 19s 159ms/step - loss: 2.0562 - acc: 0.5187 - val_loss: 0.7042 - val_acc: 0.5410
Epoch 2/30
120/120 [==============================] - 19s 161ms/step - loss: 0.7872 - acc: 0.5633 - val_loss: 0.5844 - val_acc: 0.7250
Epoch 3/30
120/120 [==============================] - 20s 167ms/step - loss: 0.5749 - acc: 0.7410 - val_loss: 0.4391 - val_acc: 0.8240
Epoch 4/30
120/120 [==============================] - 20s 171ms/step - loss: 0.4715 - acc: 0.8283 - val_loss: 0.3304 - val_acc: 0.8470
Epoch 5/30
120/120 [==============================] - 20s 170ms/step - loss: 0.3836 - acc: 0.8583 - val_loss: 0.3751 - val_acc: 0.8510
Epoch 6/30
120/120 [==============================] - 21s 171ms/step - loss: 0.3231 - acc: 0.8757 - val_loss: 0.3061 - val_acc: 0.8700
Epoch 7/30
120/120 [==============================] - 21s 172ms/step - loss: 0.3506 - acc: 0.8770 - val_loss: 0.3845 - val_acc: 0.8830
Epoch 8/30
120/120 [==============================] - 20s 169ms/step - loss: 0.3075 - acc: 0.8807 - val_loss: 0.5800 - val_acc: 0.7920
Epoch 9/30
120/120 [==============================] - 21s 172ms/step - loss: 0.2814 - acc: 0.8827 - val_loss: 0.3613 - val_acc: 0.9000
Epoch 10/30
120/120 [==============================] - 20s 170ms/step - loss: 0.2700 - acc: 0.8943 - val_loss: 0.2669 - val_acc: 0.8980
Epoch 11/30
120/120 [==============================] - 20s 170ms/step - loss: 0.2536 - acc: 0.9050 - val_loss: 0.3057 - val_acc: 0.9060
Epoch 12/30
120/120 [==============================] - 21s 172ms/step - loss: 0.2607 - acc: 0.9030 - val_loss: 0.4671 - val_acc: 0.8230
Epoch 13/30
120/120 [==============================] - 20s 170ms/step - loss: 0.2545 - acc: 0.8963 - val_loss: 0.2691 - val_acc: 0.8950
Epoch 14/30
120/120 [==============================] - 20s 170ms/step - loss: 0.2448 - acc: 0.9057 - val_loss: 0.3083 - val_acc: 0.8950
Epoch 15/30
120/120 [==============================] - 21s 172ms/step - loss: 0.2597 - acc: 0.9040 - val_loss: 0.6142 - val_acc: 0.8640
Epoch 16/30
120/120 [==============================] - 20s 170ms/step - loss: 0.2814 - acc: 0.9077 - val_loss: 0.3567 - val_acc: 0.8900
Epoch 17/30
120/120 [==============================] - 20s 171ms/step - loss: 0.2536 - acc: 0.9117 - val_loss: 0.5345 - val_acc: 0.8760
Epoch 18/30
120/120 [==============================] - 21s 174ms/step - loss: 0.2194 - acc: 0.9133 - val_loss: 0.3910 - val_acc: 0.9050
Epoch 19/30
120/120 [==============================] - 20s 171ms/step - loss: 0.2260 - acc: 0.9140 - val_loss: 0.3181 - val_acc: 0.9180
Epoch 20/30
120/120 [==============================] - 20s 171ms/step - loss: 0.2273 - acc: 0.9190 - val_loss: 0.4157 - val_acc: 0.8670
Epoch 21/30
120/120 [==============================] - 21s 176ms/step - loss: 0.2414 - acc: 0.9193 - val_loss: 0.3636 - val_acc: 0.8940
Epoch 22/30
120/120 [==============================] - 21s 175ms/step - loss: 0.2429 - acc: 0.9177 - val_loss: 0.3333 - val_acc: 0.8340
Epoch 23/30
120/120 [==============================] - 21s 175ms/step - loss: 0.2294 - acc: 0.9253 - val_loss: 0.2759 - val_acc: 0.8870
Epoch 24/30
120/120 [==============================] - 21s 176ms/step - loss: 0.2278 - acc: 0.9283 - val_loss: 0.4554 - val_acc: 0.9130
Epoch 25/30
120/120 [==============================] - 21s 174ms/step - loss: 0.4238 - acc: 0.9170 - val_loss: 1.0717 - val_acc: 0.8620
Epoch 26/30
120/120 [==============================] - 21s 172ms/step - loss: 0.1958 - acc: 0.9353 - val_loss: 0.6445 - val_acc: 0.9050
Epoch 27/30
120/120 [==============================] - 22s 183ms/step - loss: 0.1963 - acc: 0.9357 - val_loss: 1.3395 - val_acc: 0.8750
Epoch 28/30
120/120 [==============================] - 22s 183ms/step - loss: 0.1951 - acc: 0.9363 - val_loss: 0.3746 - val_acc: 0.8870
Epoch 29/30
120/120 [==============================] - 21s 176ms/step - loss: 0.2152 - acc: 0.9293 - val_loss: 1.4299 - val_acc: 0.8800
Epoch 30/30
120/120 [==============================] - 21s 171ms/step - loss: 0.1906 - acc: 0.9350 - val_loss: 0.3964 - val_acc: 0.8950
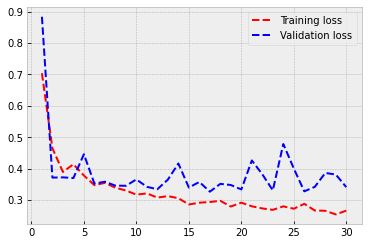
As you can see, overfitting starts to be an issue again. But our validation performance is outstanding! The model is correct 90 % of the time.
plt.style.use('bmh')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'r--', label='Training acc')
plt.plot(epochs, val_acc, 'b--', label='Validation acc')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'r--', label='Training loss')
plt.plot(epochs, val_loss, 'b--', label='Validation loss')
plt.legend()
plt.show()
As the last step, let’s check the model’s performance with the test set.
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(os.path.join(base_dir,'test'),
target_size=(150, 150),
batch_size=25,
class_mode='binary')
Found 1000 images belonging to 2 classes.
model.evaluate(test_generator)
40/40 [==============================] - 5s 115ms/step - loss: 0.3634 - acc: 0.9000
[0.3634353578090668, 0.8999999761581421]
Our model is correct 90 % of the time!
