1. Introduction to natural language processing¶
Natural language processing (NLP) is a collective term referring to computational processing of human languages. It includes methods that analyse human-produced text, and methods that create natural language as output. Compared to many other machine learning tasks, natural language processing is very challenging, as human language is inherently ambiguous, ever-changing, and not well-defined.

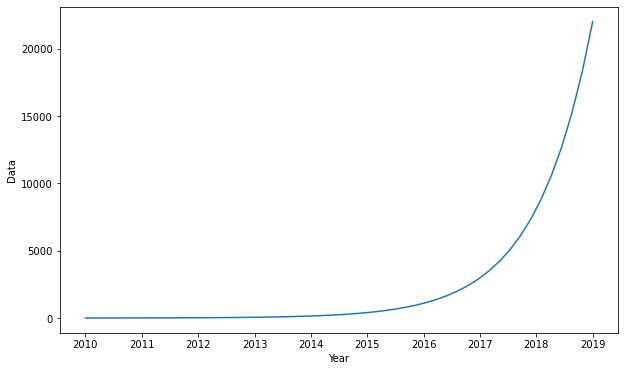
There is a need for better and better NLP-algorithms, as information in the textual format is increasing exponentially.
Until 2014, core NLP techniques were dominated by linear modelling approaches that use supervised learning. Key algorithms were simple neural networks, support vector machines and logistic regression, trained over high dimensional and sparse feature vectors (bag-of-words -vectors).
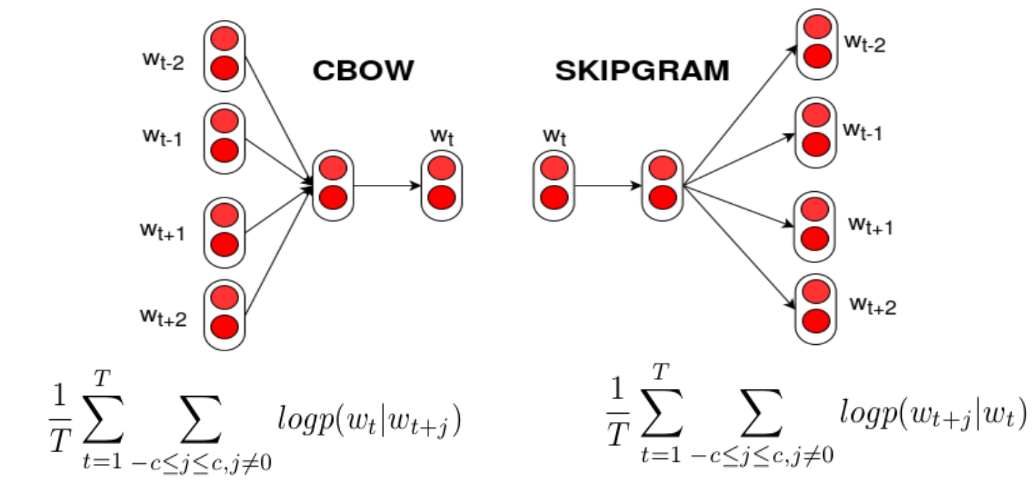
Around 2014, the field has started to see some success in switching from linear models over sparse inputs to nonlinear complex neural network models over dense inputs. A key difference is how words are presented as relatively low-dimensional vectors that contain semantic information about the words. Two key training algorithms are continuous-bag-of-words and skip-gram -algorithms.
The CBOW model architecture tries to predict the current target word (the centre word) based on the source context words (surrounding words).
The Skip-gram model architecture usually tries to achieve the reverse of what the CBOW model does. It tries to predict the source context words (surrounding words) given a target word (the centre word).
Some of the neural-network techniques are generalisations of the linear models and can be just replaced in place of the linear classifiers. Others have a totally new approach for a natural language processing task and provide new modelling opportunities. In particular, a family of approaches based on recurrent neural networks (RNNs) removes the reliance on the Markov assumption that was prevalent in sequence models, allowing to condition on arbitrarily long sequences and produce effective feature extractors. This enables the models to analyse whole sentences (and even more) instead of words, which has led to breakthroughs in language modelling, automatic machine translation, and various other applications.
Also, recent transformers-based models have achieved revolutionary results. The success of the architecture is based on a concept called attention that improves the learning by focusing on the key features and ignoring features that do not help in the task at hand. This conceptually simple innovation is largely behind the success of pre-trained models like BERT and GPT-3. The transformer is an architecture for transforming one sequence into another one with the help of two parts (Encoder and Decoder), but it differs from the previously described/existing sequence-to-sequence models because it does not imply any recurrent architectures.
(The Markov assumption means that The Markov property holds. A stochastic process has the Markov property if the conditional probability distribution of future states of the process (conditional on both past and present states) depends only upon the present state, not on the sequence of events that preceded it.)
1.1. Topic models¶
A topic model is a type of statistical model for inferring the “topics” or “themes” that occur in a collection of documents. Topic modelling is a popular tool for the discovery of hidden semantic structures in a text body. Topic models assume that there are typical words that appear more frequently in a document with a certain topic. Moreover, some words are especially rare for a certain topic and for some words, there is no difference between a document with the topic and other documents. The “topics” produced by topic modelling techniques are clusters of similar words. For example, a very popular topic model called Latent Dirichlet Allocation assumes that documents are distributions of topics and topics are distributions of words.

1.2. Neural network models¶
Neural language models almost always use continuous representations or embeddings of words to make their predictions. These embeddings are usually implemented as layers in a neural language model. The embeddings help to alleviate the curse of dimensionality in language modelling: larger corpus –> larger vocabulary –> exponentially larger number of possible sequences of words.
Neural language models represent words in a distributed way, as a combination of weights in a neural network. Typical neural network architectures are feed-forward, recurrent, LSTM and transformers architectures.
1.3. Pretrained language models¶

1.3.1. BERT¶
Bidirectional Encoder Representations from Transformers (BERT) is a pre-trained NLP model developed by Google.
The original English-language BERT model comes with two pre-trained general types: (1) the BERTBASE which uses BooksCorpus with 800M words, and (2) the BERTLARGE that uses English Wikipedia with 2,500M words.
At the time introduction, BERT achieved state-of-the-art in many NLP tasks, like language understanding and question answering. BERT started the revolution of modern language models.
(In the picture above is Elmo, not Bert. However, there is also a language model called Elmo:allennlp.org
1.3.2. GPT-3¶
GPT-3 is the current state-of-the-art language model that has achieved revolutionary results. It is also the largest ML model to date, with 175 billion parameters. It was trained with data that has 499 billion tokens (words). For example, GPT-3 can create news articles that are difficult to distinguish from human-created news. It is also able to have conversations with a human. However, despite its’ stellar performance in creating meaningful text, it still does not understand anything that it is saying. Below is an example article generated by GPT-3.
